
 and licensed under a Creative Commons Attribution-ShareAlike 4.0 International License.
and licensed under a Creative Commons Attribution-ShareAlike 4.0 International License.
|
Teacher's Study Guide for Lesson Nineteen
by Dr Jamie Love |
|
Sir Archibald Garrod suggested that some human diseases were caused by "inborn errors of metabolism".
Beadle and Tatum, irradiated Neurospora with X-rays and produced
"mutants" that would die unless their medium was supplemented with B6.
A particular gene codes for the synthesis of one particular enzyme.
The "one gene - one enzyme hypothesis"
and it is the foundation of molecular genetics but becomes "one gene
- one product".
|
Frederick Griffith mixed dead (heat killed) lethal bacteria with live harmless
bacteria and injected the mixture into mice. The mice died! These "transformed" bacteria
remained lethal and passed the lethal trait to their offspring,
therefore, this "transforming material" is the genetic
material.
Oswald Avery lysed (broke open) the lethal bacteria and separated the bacterial
components into its parts - lipids, polysaccharides, proteins
and nucleic acids.
|  |
James Watson and Francis Crick discovered the structure of DNA (using important data collected by Rosalind Parkers) and published their discovery in 1953.
All genetic information is contained in nucleic acids and these are made of three types of molecules …
|
Carbon 1 (C1) is where the base is attached.
Carbon 2 (C2) tells you if it is a ribose or deoxyribose. In deoxyribose "de oxy" is missing. Carbon 3 (C3) is the point of attachment for more nucleotides. Carbon 4 (C4) completes the ring via an oxygen which bridges to the carbon 1 (C1). Carbon 5 (C5) hangs away from the ring and is the point of attachment for its phosphate(s). |  |
Phosphates and sugars make up the "backbone" of DNA
and RNA.
They form a chain that runs from a phosphate on the previous molecule, to C3 (the right foot
and hip) through C4 (the right shoulder) to C5 (the right hand
holding a mitten for grabbing the next molecule).
There are two types of nitrogenous bases.
are a single hexagonal ring of carbons and nitrogens.  Pyrimidine | are double rings made of a pyrimidine with a pentagon added.  Purine |
We refer to the carbon 1 in sugar as
"carbon one prime" and the carbon in the bases simply
as "carbon one".
We use the abbreviation ' (a little dash of an apostrophe) to signify prime so the sugar runs 3'
to 5' with the 4' shoulder in between.
DNA has four different bases (and abbreviations).
Adenine (A) and guanine (G) are purines which are distinguished and identified by the oxygen (O) or ammonia (NH2) attached at specific positions.
 |  |
Thymine (T) and cytosine (C) are pyrimidines and distinguished and identified by the oxygen (O), ammonia (NH2) or methyl (CH3) attached at specific positions.
 |
 |
|
RNA (ribonucleic acid) does not have thymine. Instead, it has
the base uracil (U).
|  |
Sugar's carbon one (1') is the site where bases are attached.
Any base (A, G, C, T or U) can attach to either sugar (ribose
or deoxyribose) to form a "double molecule" called a
nucleoside.
The bond linking these molecules (sugar and base) is called a glycoside bond.
If the sugar is ribose we have a ribonucleoside but if the sugar is deoxyribose we have a deoxyribonucleoside.
Here (below) are the four ribonucleosides. Notice that they all have a hydroxyl group (OH) at the C2' position.
 |
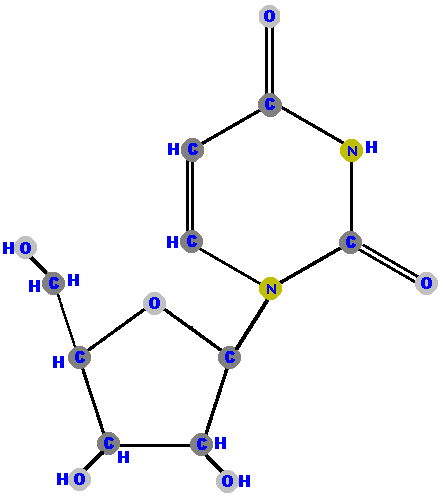 |
 |
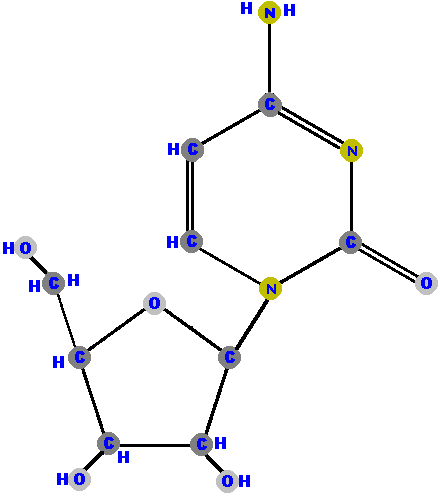 |
Below are the four deoxyribonucleosides. Notice that they do NOT have a hydroxyl group (OH) at the C2' position.
 |
 |
 |
 |
Phosphate can be attached to the sugar though the 5' carbon to
give a "triple molecule" of phosphate, sugar and base
called a nucleotide.
[Nucleoside stops
at sugar but nucleotide takes
a phosphate.]
Nucleotides are the fundamental "units" of the larger
molecules of DNA and RNA.
Here are the four ribonucleotides (made of ribose with a phosphate at the 5' carbon and one of the four possible bases on the 1' carbon).
 |
 |
 |
 |
Here are the four deoxyribonucleotides (made of deoxyribose with a phosphate at the 5' carbon and one of the four possible bases on the 1' carbon).
 |
 |
 |
 |
|
| (5'-monophosphate) | |
(5'-monophosphate) | ||
Nucleoside diphosphates have a pair of phosphates (PO3-PO4) and nucleoside triphosphates have a triplet of phosphates (PO3-PO3-PO4) attached to the 5' carbon of the sugar.
|
Adenosine triphosphate (ATP) is often called the "power molecule"
of life because it is the most common source of chemical energy
for living things!
ATP is made of an adenine base attached to
a ribose via C1' (adenosine) with a triphosphate (PO3-PO3-PO4)
attached at the sugar's 5'.
All nucleoside triphosphates are high energy and unstable but once they lose their second and third phosphates (ATP->ADP + P ->AMP + P) the remaining nucleoside monophosphate is very stable and can no longer provide any energy. |

|
DNA is deoxyribonucleic acid. RNA is ribonucleic acid.
A molecule that releases hydrogens is said to be an acid (by definition) and by
releasing the hydrogens it takes on a negative charge (by the
laws of electrostatics).
The phosphates in DNA and RNA cause these molecules to have a (net) negative charge (and the reason they
are acids).
|
Nucleic acids are polymers (chains) of nucleotides called polynucleotides.
This drawing shows the double bonds of the phosphates that were missing in the previous drawings. It also shows, in red, the negative charges near the phosphates.
This linkage is between the 5' of one sugar and the
3' of another sugar with its one phosphate (PO4-1) acting as the
linker.
Polymers of nucleic acids (DNA and RNA) are nucleotides joined by phosphodiester bonds. |  |
|
A stick diagram reminds us of the zigzag backbone
of the sugar-phosphates. The terminal OH, represented
on the 3' extreme, is the only OH in the backbone.
Only one phosphate is free (at the 5' end). |  |
| A simpler representation is to type the sequence with the phosphates and bases abbreviated, all in a straight line. It shows all the phosphates including the one at the 5' end. The other side of the molecule does NOT have a phosphate so it must have a hydroxyl (OH) there. |  |
| Accept that, "sequences of bases are always written such that the left side is the 5' end (with a dangling phosphate) and the right hand side is the 3' end (with the OH group). |  |
DNA is usually composed of a pair of strands!
Chargaff discovered that the DNA from any particular
cell has equal amounts purines and pyrimidines.
The amount of adenine (A) equals that amount
of thymine (T) and the amount of guanine (G) equals the amount
of cytosine (C). This is called "Chargaff's rule".
|
DNA is a double-helix composed of two strands of polynucleotides.
DNA is like a ladder with the sugar-phosphate backbone of the two polynucleotides as the supporting sides of the ladder and with the bases as the rungs (steps).
The bases forming the rungs are bound to each other
by "hydrogen bonds".
Adenine (A) and thymine (T) form two hydrogen bonds between them. Guanine (G) and cytosine (C) form three hydrogen bonds between them. Each nucleotide is attached to the next nucleotide by a phosphate group (PO4) linking the 5' carbon (5'C) of one sugar to the 3' carbon (3'C) of the next sugar. |  |
|
Notice that the strand on the right is in an opposite orientation to the one on the left.
We say the stands are "antiparallel"
meaning they run in opposite directions.
Adenine cannot form its two hydrogen bonds with thymine unless thymine is positioned "upside down". The same is true for the guanine-cytosine bonds. |  |

| The phosphodiester bonds and sugars have a restricted orientation
that cause them to twist a small amount in order to line up with
the opposite, complementary strand.
The result is that the two strands wrap around each other in a double helix. The diameter of this double-helix is only 20 angstroms. (An angstrom, is roughly the diameter of a hydrogen atom and precisely 10-10 of a meter.) Adjacent bases are separated by 3.4 angstroms along the helix axis and rotated 36 degrees from each other.
The helical structure repeats after ten nucleotides.
|  |
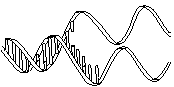
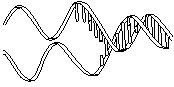
|
The molecule on the left is normal right-handed DNA.
The second image is a left-handed helix and is not the normal, natural form of DNA. Notice how its twists the wrong way. DNA has "grooves" (indented areas) running along the length of the helix caused by the bulky sugars and phosphates on the exterior and the less bulky bases inside. One groove is smaller than the other so they are called the "minor groove" and "major groove". | (Correct)  | (WRONG!)  | 
|